The LZ77 algorithm is a lossless compression method that uses a sliding window to identify and encode repetitive patterns in a data sequence. By replacing repeated occurrences with references to previous segments, it reduces file size without losing any information. This approach is particularly effective for data containing recurring patterns, such as text files, logs, and certain types of binary images.
LZ77 works by scanning a data sequence and identifying parts that have already appeared within the sliding window. This window acts as a temporary memory, holding a history of recent data to facilitate compression. The larger the window, the greater the chances of finding repetitions, which improves the compression ratio.
The algorithm begins by analyzing the data one by one and temporarily storing them in the search window. This window contains previously read characters and serves as a reference for detecting repetitive patterns. Proper management of this window is essential to ensure efficient compression while maintaining a reasonable computational complexity.
In the diagram below, binary data can be represented as a string of characters, with one byte per character.
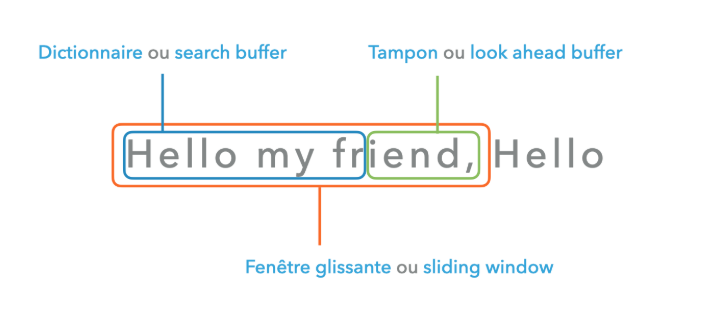
The algorithm continuously compares incoming data with those stored in the search window. When it finds a match, it measures the maximum length of the repeated pattern and records it as a triplet.
- Offset: Relative position of the pattern in the window.
- Length: Number of characters in the repeated sequence.
- Next symbol: Unique character allowing the reading process to continue.
A larger sliding window increases the chances of detecting long sequences and thus improving compression. However, an excessively large window may slow down processing and require more memory.
Once a pattern is identified, it is converted into a triplet (offset, length, symbol). This triplet replaces the repeated sequence, effectively compressing the data. If no pattern is found, a triplet (0,0,character) is generated to indicate a new, uncompressed character.
Encoding is essential to ensure that the stored information can be easily reconstructed during the decompression phase. This approach forms the basis of compression formats such as ZIP and PNG.
After each encoding, the sliding window moves forward, and the process repeats. This progressive shift allows the algorithm to exploit data repetitions and maintain efficient compression throughout the file.
In the end, we receive a list of LZ77 tokens that represents data in a compressed way.

Decompression relies on reading the encoded triplets and progressively reconstructing the original data. Each triplet indicates either a repeated sequence to copy or a unique character to add.
When a triplet indicates a repeated pattern, the algorithm refers to the sliding window to copy the corresponding sequence, thereby reconstructing the original data without any loss.
The process continues until all data is fully reconstructed. This approach ensures that each encoded character is restored to its original place, making the decompressed file identical to the initial source file.